![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2Fd192001e06ed413fb0e091ac51bca29248130453-942x942.jpg&w=256&q=75)
by Dr Ana Rojo-Echeburúa
Updated 30 November 2023
Expanding our AI Data Assistant to use Prompt Templates and Chains
![[object Object]](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2Fei1axngy%2Fproduction%2F35bf81a5ae7a76bb64e746621f64c802a9da2358-1000x462.jpg&w=2048&q=75)
Download the resources for this post here.
It is no secret that Large Language Models are revolutionising the world of AI. Start-ups across the board are swiftly integrating these models into their frameworks in order to streamline their processes and generate sales. And guess what? So can you!
In this part of our series Building an AI Data Assistant with Streamlit, LangChain and OpenAI, we'll continue our journey to simplify your data science tasks. We'll pick up from where we left off and I’ll guide you through the process of enhancing your AI Assistant.
✨ Remember that what you learn here can be applied to your own data science problems.
While we'll focus on one specific use case, you can easily adapt these techniques to your unique needs and goals!
🔗 We will be using the following use case.
🧠 Key learnings
Langchain:
- How to create prompt templates. In this tutorial, we will use them in order to streamline the process of converting a broad business challenge into a focused data science problem alongside providing suitable machine learning algorithms.
- Integration of a Wikipedia API wrapper as a tool. This will expand the capabilities of our assistant to access information.
- How to build chains. These will utilise an LLM to interact with the prompts and provide information. We will connect two chains using a sequential chain, enabling us to input a business problem and, in turn, receive a reframing of the problem in a data science framework and a curated list of algorithms suitable to solve the problem.
- Create and run a Python agent. This will be equipped with the Python REPL tool in order to write and execute code.
Streamlit
- Adding area input to create a multiline text input area.
- Implementation of a selectbox. This will allow the user to select their algorithm of choice to solve their problem, further enhancing the interactive experience.
By the end of this tutorial, you'll have a more powerful AI Assistant at your fingertips, ready to assist you in your data science projects!
🦜 New LangChain concepts
In this part of our series, we're diving into the concept of prompts, prompt templates, chains and tools in the LangChain framework.
▪️ Prompts
A prompt is a set of instructions or input provided by a user, guiding the model's response. It aids the model in comprehending context and generating coherent language-based output, such as answering questions or engaging in a conversation.
▪️ Prompt Templates
Prompt templates are pre-defined recipes for constructing prompts. These templates may include instructions, few-shot examples, and specific context and questions suitable for a given task.
LangChain provides robust tooling to create and work with these prompt templates, allowing for the seamless reuse of templates across different language models. Typically, language models expect the prompt to be either a string or a list of chat messages.
▪️ Chains
Chains are a fundamental aspect of LangChain. They are logical connections between one or more LLM instances. Chains can vary in complexity, tailored to the requirements and the specific LLMs involved. We will be exploring two types of chains: Simple Sequential Chains and Sequential Chains.
The Simple Sequential Chain comes into play when there's a single input and a single output between chains. On the other hand, the Sequential Chain is utilised when there are multiple inputs and outputs.
Prompt templates provide the structure for constructing prompts, and chains use these prompts as part of a logical sequence of interactions with LLMs. They work together to facilitate a systematic and organised approach to leveraging LLMs for various tasks within the LangChain framework.
▪️ Tools
A tool serves as a dedicated interface crafted to execute a particular task. It typically involves a function that takes a string as input and produces a string as output.
In this tutorial, we are going to explore two different tools: Wikipedia API Wrapper and Python REPL.
- Wikipedia API Wrapper: This tool is used to fetch relevant information from Wikipedia based on the user's input (prompt). It aids in gathering additional insights related to the data science problem.
- Python RELP: This tool is designed to interact with Python agent, allowing users to execute Python scripts related to the data science problem.
These tools are integral to the LangChain framework, enabling users to gather information from external sources (Wikipedia) and execute Python scripts seamlessly within the data science workflow.
🎮 Don't forget to run Streamlit!
In the terminal, making sure you are in your working directory, use the following command:
streamlit run [your_script_name.py]
👉 Replace your_script_name.py with the name of your Streamlit Python script.
🔑 Required libraries and modules
First thing we need to do, is to import the required libraries, modules and classes to continue building our AI Assistant:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain, SimpleSequentialChain, SequentialChain
from langchain.agents.agent_toolkits import create_python_agent
from langchain.tools.python.tool import PythonREPLTool
from langchain.agents.agent_types import AgentType
from langchain.utilities import WikipediaAPIWrapper
Let's go over each statement:
from langchain.prompts import PromptTemplate
This statement imports the PromptTemplate class from the prompts module within the langchain library. This module allows creating templates for prompts.
from langchain.chains import LLMChain, SimpleSequentialChain, SequentialChain
This statement imports three classes (LLMChain, SimpleSequentialChain, and SequentialChain) from the chains module within the langchain library.
These modules allow the construction and management of chains.
from langchain.agents.agent_toolkits import create_python_agent
This statement imports the create_python_agent function from the agent_toolkits module within the agents subpackage of the langchain library. This module provides a toolkit for creating agents. create_python_agent creates an agent specifically tailored for Python-related tasks.
from langchain.tools.python.tool import PythonREPLTool
This statement imports the PythonREPLTool class from the tool module within the python subpackage of the tools module in the langchain library. This module provides the Python REPL (Read-Eval-Print Loop) tool. REPL is an interactive programming environment where the user can enter commands, and the system evaluates and prints the results. PythonREPLTool is used to interact with Python code in order to write it and execute it.
from langchain.agents.agent_types import AgentType
This statement imports the AgentType class from the agent_types module within the agents subpackage of the langchain library. This module defines different types or categories of agents. An agent type determines the behaviour, capabilities, or specialisation of an agent. For example, AgentType.ZERO_SHOT_REACT_DESCRIPTION provides the agent the capability of reacting or responding to queries with zero-shot learning, involving description-based tasks.
from langchain.utilities import WikipediaAPIWrapper
This statement imports the WikipediaAPIWrapper class from the utilities module within the langchain library. This module provides wrappers that allow interactions with the Wikipedia API. The WikipediaAPIWrapper allows making requests to Wikipedia, retrieving information, or handling responses.
These statements import specific classes or functions from various modules within the langchain library, which collectively support tasks related to language modelling, agent creation, Python interactions, and Wikipedia API interactions.
✏️ Starting a new section
We are going to add a divider to separate the Exploratory Analysis section from the Data Science section, and we are going to add a header with the text 'Data Science Problem' to introduce our new section. We will also include some text to provide information about the importance of reframing the business problem into a data science problem.
But first, we need to add a conditional statement to check whether the variable user_question_dataframe is non-empty, non-zero, or non-None. If user_question_dataframe is evaluated as true, the code within the indented block will be executed.
if user_question_dataframe:
st.divider()
st.header("Data Science Problem")
st.write("Now that we have a solid grasp of the data at hand and a clear understanding of the variable we intend to investigate, it's important that we reframe our business problem into a data science problem.")
If user_question_dataframe is truthy, this code block will create a visual divider, display a header, and provide information about the importance of reframing the business problem into a data science problem.

Figure 1. Divider and header
💭 Our first prompt
Now that we have introduced our section, let’s write our first prompt. To do this, we will create a new variable called prompt and set it equal to st.text_input, including a label that says 'add your prompt here'.
prompt = st.text_input('Add your prompt here')

Figure 2. Prompt
At this point, it won't perform any action because we haven't connected our LLM yet. Let's proceed to hook it up. We need a way to trigger our prompt to our LLM. If there's a prompt, we'll create a new variable for our response and pass the prompt to the LLM. To render this back to the screen, we'll use st.write.
if prompt:
response = llm(prompt)
st.write(response)

Figure 3. Prompt response
💭 Using a prompt template
Currently, we've had to write out the entire prompt. Ideally, what we want is for our application to determine what should be generated based on a business problem the user inputs.
This is where prompt templates come in.
We want to create a prompt template that takes in our business problem and generates a prompt asking to convert the business problem into a data science problem.
To create the prompt template, we set a new variable called data_problem_template to PromptTemplate. We define the input variable as business_problem and the template as a string, asking to convert the business problem into a data science problem, with {business_problem} as a placeholder for the variable.
data_problem_template = PromptTemplate(
input_variables=['business_problem'],
template='Convert the following business problem into a data science problem: {business_problem}.'
)
This ensures that when we use this prompt template, we only need to pass through a business problem, and it will prompt-format it accordingly with our business problem.
⛓️ Adding our first chain
Now that we have our prompt template, to use it effectively, we're going to employ an LLM chain.
We create a data_problem_chain and set it equal to LLMChain. We need to pass through our LLM to the LLM chain, so we use 'llm=llm'. Then, we set our prompt to be data_problem_template, so prompt = data_problem_template. Instead of running the LLM directly, we'll use the run method on our data_problem_chain based on that prompt. Setting verbose=True here allows you to see the chain running as it progresses.
data_problem_chain = LLMChain(llm=llm, prompt=data_problem_template, verbose=True)
if prompt:
response = data_problem_chain.run(business_problem=prompt)
st.write(response)

Figure 4. Prompt template
This is the advantage of using prompt templates; they significantly simplify the process.
📝 Introducing our second prompt template
For now, we've only generated a data science problem. However, we also want a list of suitable machine learning models.
This is where chains truly come in handy.
Currently, we're using a single chain. What we can do is chain several of these together, sequentially bringing them together to perform multiple tasks.
Now, let's create another prompt template. This next template is all about generating a list of suitable machine learning algorithms to solve the problem. We'll duplicate the existing prompt template, currently named data_problem_template, and convert it to model_selection_template. The input for our script template is going to be our data science problem. So, our input variable here is actually going to be:
"Give a list of machine learning algorithms that are suitable to solve this problem: {data_problem}"
Then, we'll pass this data_problem variable into our prompt template.
model_selection_template = PromptTemplate(
input_variables=['data_problem'],
template='Give a list of machine learning algorithms that are suitable to solve this problem: {data_problem}'
)
You can see how these prompt templates can really come in handy. It means that you've already got the prompt formatted; you just need to pass through the context-specific variables.
🔗 Adding another chain
Just as we did before with our first prompt template, to make it functional, we need to create another chain. However, this chain will be the model_selection_chain.
We'll take our model_selection_template and set it as our prompt.
We have two prompt templates and two chains:
data_problem_template = PromptTemplate(
input_variables=['business_problem'],
template='Convert the following business problem into a data science problem: {business_problem}.'
)
model_selection_template = PromptTemplate(
input_variables=['data_problem'],
template='Give a list of machine learning algorithms that are suitable to solve this problem: {data_problem}.'
)
data_problem_chain = LLMChain(llm=lmm, prompt=data_problem_template, verbose=True)
model_selection_chain = LLMChain(llm=llm, prompt=model_selection_template, verbose=True)
🖇️ Linking our chains together with a simple sequential chain
We need a way to join these chains together because, right now, they're operating independently; they are not interacting with each other.
This is where we use the simple sequential chain.
We'll create a new instance of our sequential chain and set it equal to SimpleSequentialChain.
There's one positional argument that we need to set for our simple sequential chain, and that is the chains positional argument. It's just a list of all the sequential chains. Order is crucial here. We're specifying to run the data_problem_chain first, which generates our data science problem, and then run the next chain. The output of our data_problem_chain will then get passed to our model_selection_chain. It's a simple sequential chain where one output goes to the next chain.
sequential_chain = SimpleSequentialChain(chains=[data_problem_chain, model_selection_chain], verbose=True)
Now, we've got two templates, two chains, and also a simple sequential chain that chains them all together.
What we need to do now is change response = data_problem_chain.run(business_problem=prompt) to response = sequential_chain.run({prompt}).
if prompt:
response = sequential_chain.run({prompt})
st.write(response)
Note that the syntax is slightly different for the input.
This should now run the data_problem_chain, generate the output, then pass the data science problem to the model_selection_chain and generate the list of suitable machine learning algorithms.
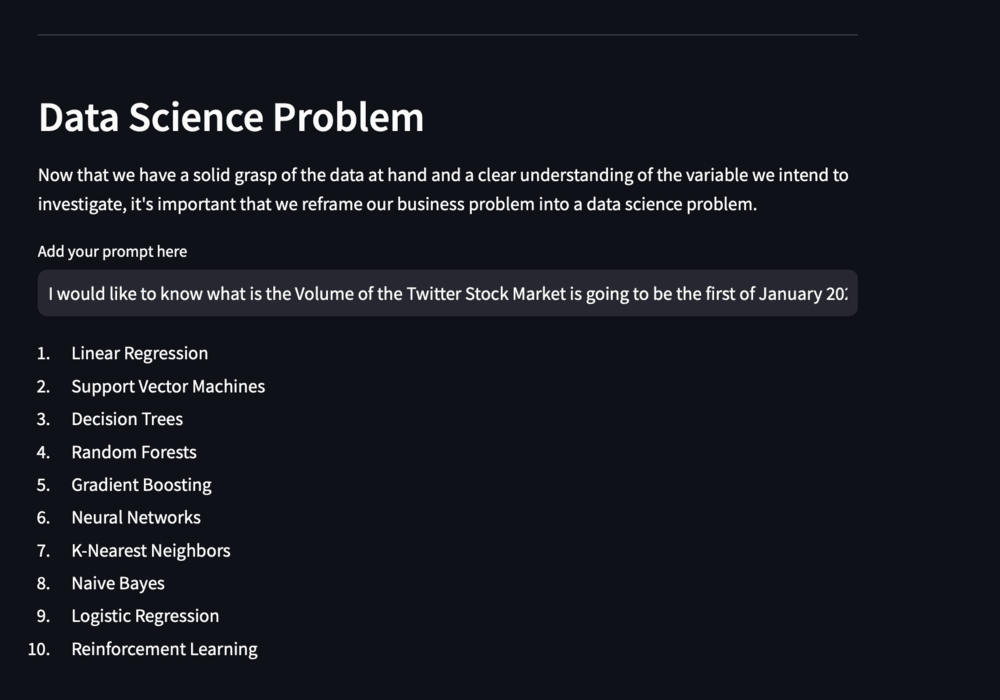
Figure 5. SimpleSequentialChain
🪄 Outputting multiple outputs, using a sequential chain
The simple sequential chain is only outputting the list of machine learning algorithms; it's not actually outputting the data science problem. This limitation arises because a simple sequential chain manages only one single input and one single output.
What we can do is swap this out for a sequential chain, which allows us to get multiple sets of outputs. Sequential chains are capable of managing multiple inputs and outputs simultaneously.
However, to make the sequential chain work, we do need to specify output keys for each of our different chains.
The output key for our data_problem_chain is going to be data_problem. We also need to update our model_selection_chain; the output key there is going to be model_selection.
We can then replace our simple sequential chain with a sequential chain and specify that our input variables for the sequential chain will be purely the business_problem, and the output variables will include multiple output variables: data_problem and model_selection. This allows us to obtain multiple outputs from our sequential chain instead of just one.
When using a sequential chain, we need to pass through a dictionary. Our dictionary is going to take business_problem as a key, as well as our prompt. To get our data problem and model selection, we can access them separately from our response.
data_problem_chain = LLMChain(llm=llm, prompt=data_problem_template, verbose=True, output_key='data_problem')
model_selection_chain = LLMChain(llm=llm, prompt=model_selection_template, verbose=True, output_key='model_selection')
sequential_chain = SequentialChain(chains=[data_problem_chain, model_selection_chain], input_variables=['business_problem'], output_variables=['data_problem', 'model_selection'], verbose=True)
if prompt:
response = sequential_chain({'business_problem': prompt})
st.write(response['data_problem'])
st.write(response['model_selection'])

Figure 6. SequentialChain
🔨 Adding our first tool: Wikipedia API Wrapper
One thing that makes LangChain really interesting is its ability to integrate tools.
We are going to import the Wikipedia API wrapper tool, which allows us to make API calls to the Wikipedia API.
But why would this be useful? It turns out that the model we are using, gpt-3.5-turbo, is trained up to September 2021. If there are any new algorithms released after that date, the LLM itself won’t have access to that information. The Wikipedia API wrapper allows us to access information released after September 2021 on Wikipedia. If there is any relevant and suitable algorithm that has been released after that date, the wrapper would be able to access that information.
What we need to do next is to update our prompt templates. Our prompt template is no longer only going to take in a data science problem. We're going to take in some Wikipedia research as well, so what we'll be able to do is prompt with Wikipedia as a backup.
template='Give a list of machine learning algorithms that are suitable to solve this problem: {data_problem}, while using this Wikipedia research: {wikipedia_research}.'
The next thing that we need to do is create an instance of our Wikipedia API wrapper. So what is going to happen is that we will pass our business_problem to our data_problem_chain; it'll generate a data science problem. Then we will take that data science and the Wikipedia research and pass it through to our model_selection_chain.
We are also going to create functions and cache them to organise things a little better:
@st.cache_resource
def wiki(prompt):
wiki_research = WikipediaAPIWrapper().run(prompt)
return wiki_research
@st.cache_data
def prompt_templates():
data_problem_template = PromptTemplate(
input_variables=['business_problem'],
template='Convert the following business problem into a data science problem: {business_problem}.'
)
model_selection_template = PromptTemplate(
input_variables=['data_problem', 'wikipedia_research'],
template='Give a list of machine learning algorithms that are suitable to solve this problem: {data_problem}, while using this Wikipedia research: {wikipedia_research}.'
)
return data_problem_template, model_selection_template
@st.cache_data
def chains():
data_problem_chain = LLMChain(llm=llm, prompt=prompt_templates()[0], verbose=True, output_key='data_problem')
model_selection_chain = LLMChain(llm=llm, prompt=prompt_templates()[1], verbose=True, output_key='model_selection')
sequential_chain = SequentialChain(chains=[data_problem_chain, model_selection_chain], input_variables=['business_problem', 'wikipedia_research'], output_variables=['data_problem', 'model_selection'], verbose=True)
return sequential_chain
@st.cache_data
def chains_output(prompt, wiki_research):
my_chain = chains()
my_chain_output = my_chain({'business_problem': prompt, 'wikipedia_research': wiki_research})
my_data_problem = my_chain_output["data_problem"]
my_model_selection = my_chain_output["model_selection"]
return my_data_problem, my_model_selection
We also need to tidy up the prompt part of our code. Instead of add your prompt here, we are going to swap it for What is the business problem you would like to solve? Also to give more room to the user to write this down, we will use st.text_area instead of st.text_input.
prompt = st.text_area('What is the business problem you would like to solve?')

Figure 7. Text area
We also need to tidy up the if prompt: statement:
if prompt:
wiki_research = wiki(prompt)
my_data_problem = chains_output(prompt, wiki_research)[0]
my_model_selection = chains_output(prompt, wiki_research)[1]
st.write(my_data_problem)
st.write(my_model_selection)
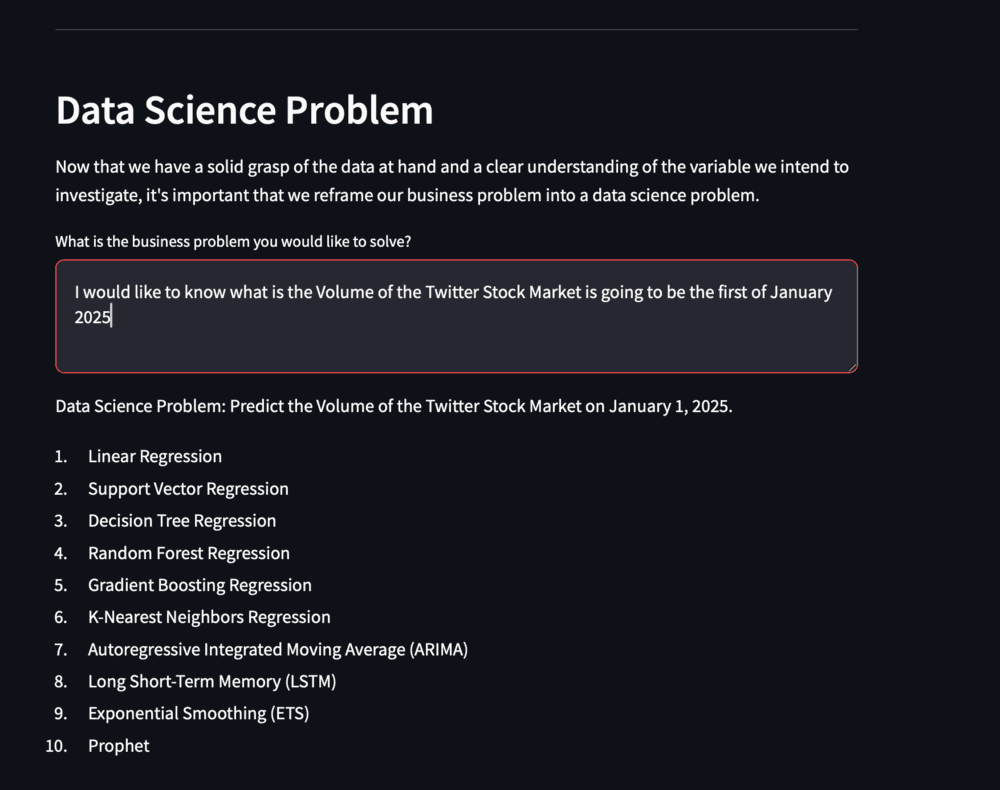
Figure 8. Chains
Note that now the list of outputted algorithms is more refined.
🌐 @st.cache_data vs @st.cache_resource
We have used the @st.cache_resource decorator before our wiki function and not @st.cache_data. It turns out that the decorator @st.cache_data is designed to cache functions that return data (e.g., dataframe transforms, database queries, ML inference..). On the other hand, st.cache_resource is designed to cache global resources like ML models or database connections – unserialisable objects that you don't want to load multiple times. @st.cache_resource turns out to be more suitable for our function wiki.
📦 Creating a selection box
Now that we have a list of suitable algorithms, it would be great if the user could select their choice of algorithm in order to do predictions.
In order to enhance user experience, we are going to implement a selectbox with Streamlit.
In Streamlit, the selectbox function is used to create a dropdown select box, allowing users to choose from a list of options. It provides a simple and interactive way to get input from users by presenting them with a set of choices.
Here's a breakdown of how to use st.selectbox in Streamlit:
import streamlit as st
# Define a list of options
options = ("Option 1", "Option 2", "Option 3")
# Create a select box and store the selected value
selected_option = st.selectbox("Select an option", options)
# Display the selected option
st.write("You selected:", selected_option)
Let's go through that code:
- Label (
"Select an option"): This is the label that is displayed next to the select box, instructing the user on what action to take. - Options (
options): This is a list or any iterable containing the available choices. In the example, theoptionslist contains three strings, but it could be numbers, objects, or any other type of data. - Selected Value (
selected_option): This variable holds the currently selected value from the select box. Initially, it will be set to the default value or the value at the specified index (if provided). - Displaying the Selected Value (
st.write("You selected:", selected_option)): This line is used to display the selected option. You might want to use the selected value in further processing or simply show it to the user.
In order to pass our list of algorithms as option we create the following function:
@st.cache_data
def list_to_selectbox(my_model_selection_input):
algorithm_lines = my_model_selection_input.split('\n')
algorithms = [algorithm.split(':')[-1].split('.')[-1].strip() for algorithm in algorithm_lines if algorithm.strip()]
algorithms.insert(0, "Select Algorithm")
formatted_list_output = [f"{algorithm}" for algorithm in algorithms if algorithm]
return formatted_list_output
Let’s explain this code:
list_to_selectbox(my_model_selection_input): This function takes a string (my_model_selection_input) as input, which contains the information suitable machine learning algorithms provided by our chain.algorithm_lines = my_model_selection_input.split('\n'): It splits the input string into a list of lines. Each line is assumed to represent information about a specific machine learning algorithm.algorithms = [algorithm.split(':')[-1].split('.')[-1].strip() for algorithm in algorithm_lines if algorithm.strip()]: It processes each line to extract the name of the machine learning algorithm. It removes leading and trailing whitespaces and extracts the last part after the colon (:) and the last part after the last dot (.).algorithms.insert(0, "Select Algorithm"): It inserts the string "Select Algorithm" at the beginning of thealgorithmslist. This is often used as a placeholder in dropdown select boxes.formatted_list_output = [f"{algorithm}" for algorithm in algorithms if algorithm]: It formats each algorithm name into a string, and it filters out any empty strings from the list.return formatted_list_output: The formatted list of algorithm names is then returned.
This function prepares our list of machine learning algorithms for use in a select box, for a user interface where the user can choose a machine learning algorithm from a dropdown menu.
Then, we can use this function to format our list of algorithms and pass it as the options for the select box:
formatted_list = list_to_selectbox(my_model_selection)
selected_algorithm = st.selectbox("Select Machine Learning Algorithm", formatted_list)
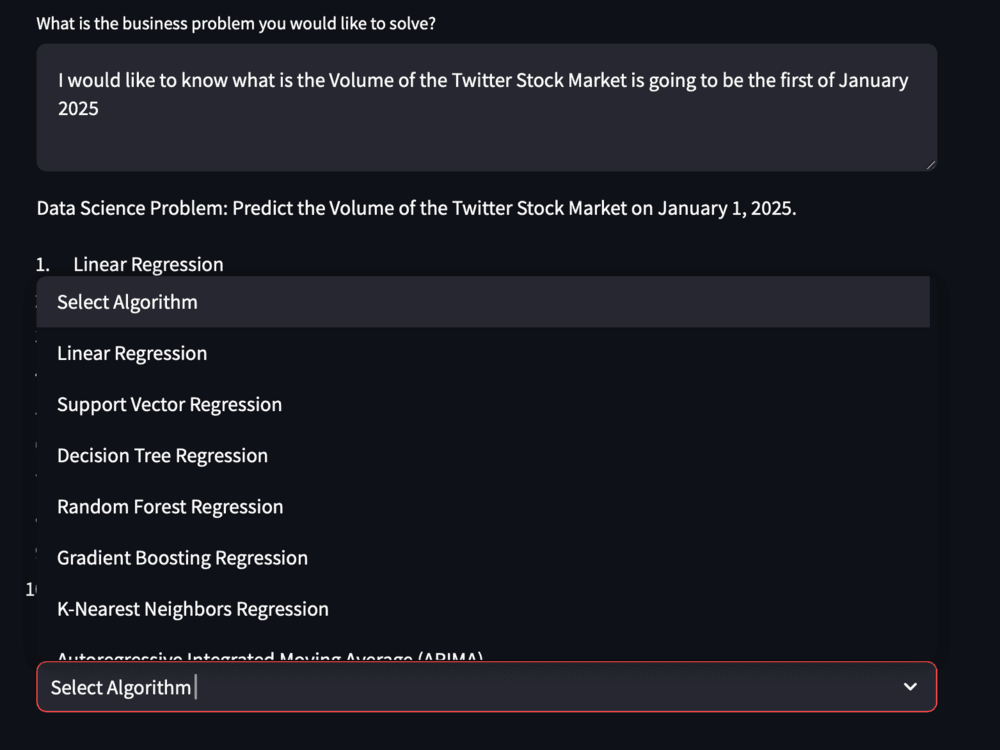
Figure 9. SelectBox
These two lines of code work together to create a dropdown select box in the app, allowing the user to choose a machine learning algorithm from a list of options generated by the list_to_selectbox function. The selected algorithm is then stored in the variable selected_algorithm for further use in the application.
🔎 Creating a Python agent
The Python Agent is responsible for writing and executing Python code based on the user's input. Its versatile capabilities make it a crucial component in enabling our AI Assistant to dynamically generate and execute Python solutions.
Let's explore the code that initialises and configures the Python Agent.
@st.cache_resource
def python_agent():
agent_executor = create_python_agent(
llm=llm,
tool=PythonREPLTool(),
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
)
return agent_executor
-
create_python_agent: This function is part of the LangChain library and is used to create a Python Agent. It takes several parameters:llm: The language model to be used by the agent (llmin this case).tool: The tool associated with the agent, in this case, a PythonREPLTool. This tool facilitates interaction with Python code.verbose: A boolean parameter indicating whether to display detailed information during execution (set toTruein this case).agent_type: Specifies the type of the agent. Here, it's set toAgentType.ZERO_SHOT_REACT_DESCRIPTION, indicating that the agent does a reasoning step before acting.handle_parsing_errors: Another boolean parameter, determining whether parsing errors should be handled. It's set toTrueto handle parsing errors.
-
return agent_executor: The Python Agent, configured with the specified parameters, is returned by the function.
🐍 The PythonREPLTool tool
The PythonREPLTool is a tool designed for interacting with Python code within the LangChain framework. It plays a pivotal role in enabling the Python Agent to execute Python scripts, providing a seamless and efficient way for users to interact with the Python REPL (Read-Eval-Print Loop).
The primary function of the PythonREPLTool is to execute Python code snippets. Users can input Python commands or scripts, and the tool facilitates their execution.
The tool integrates with the underlying language model (llm in this case), allowing the Python Agent to understand and respond to user queries related to Python programming.
The PythonREPLTool is chosen as the tool of choice for the Python Agent. Its capabilities align with the objective of our AI Assistant, which involves generating and executing Python code based on user prompts.
⭐ Using Our Python Agent to give a solution to our problem
Now that we have initialised our Python agent, we can use it to provide a solution to our problem using the algorithm chosen by the user. To do that, we will utilise the .run method on our Python agent and request the generation of a Python script to address our data problem using the selected algorithm and our dataset. For this purpose, we can define the following function:
@st.cache_data
def python_solution(my_data_problem, selected_algorithm, user_csv):
solution = python_agent().run(
f"Write a Python script to solve this: {my_data_problem}, using this algorithm: {selected_algorithm}, using this as your dataset: {user_csv}."
)
return solution
In order to integrate this into our code workflow, we can write the following code:
if selected_algorithm is not None and selected_algorithm != "Select Algorithm":
st.subheader("Solution")
solution = python_solution(my_data_problem, selected_algorithm, user_csv)
st.write(solution)
Let's go over this piece of code:
if selected_algorithm is not None and selected_algorithm != "Select Algorithm":This condition checks whetherselected_algorithmis notNoneand not equal to the default value"Select Algorithm". This condition ensures that a valid machine learning algorithm has been selected by the user.- If the condition is true, the following actions are performed:
st.subheader("Solution"): Streamlit command to display a subheader with the text "Solution." This is used to visually separate or label the section where the solution will be presented.solution = python_solution(my_data_problem, selected_algorithm, user_csv): Invokes thepython_solutionfunction with parametersmy_data_problem,selected_algorithm, anduser_csv. This function generates and executes a Python script based on the provided inputs, and the result is stored in the variablesolution.st.write(solution): Streamlit command to display the contents of thesolution. This could include any output or information generated by the Python script. The result is presented on the Streamlit app.
This code ensures that a valid machine learning algorithm has been selected by the user (selected_algorithm is not None and not equal to the default value). If a valid selection is made, it triggers the execution of the Python solution script using the python_solution function and displays the result on the Streamlit app.
Example 1 : Linear Regression
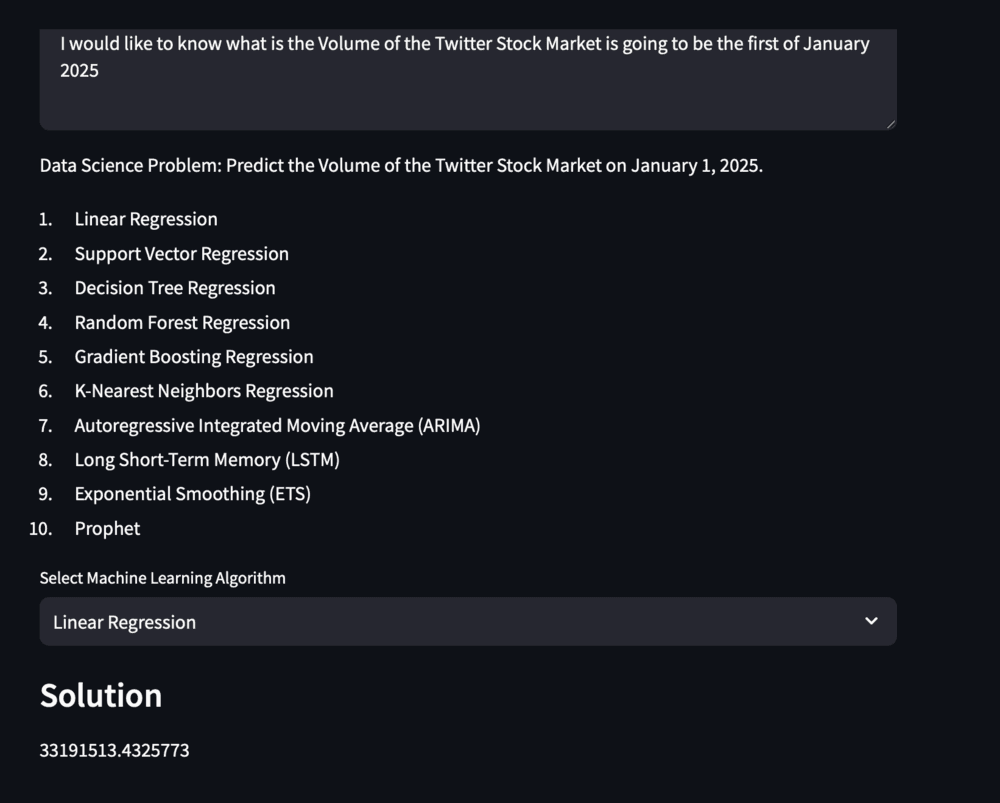
Figure 10. LRoutout
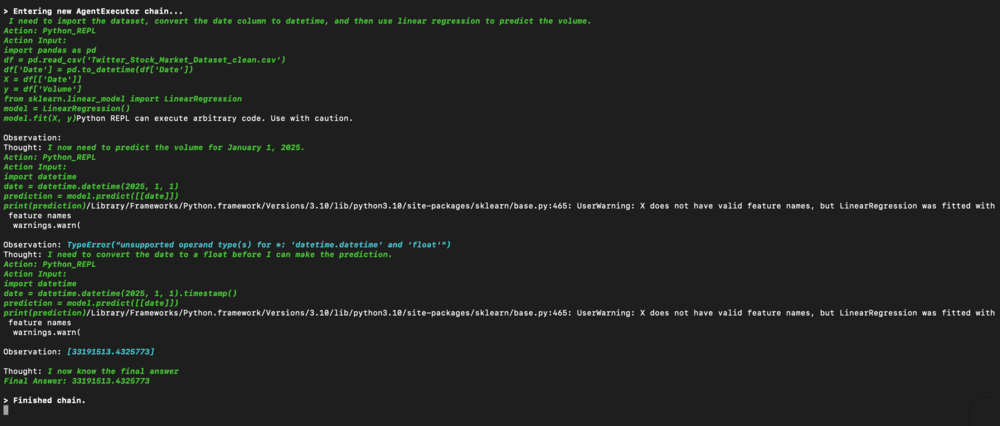
Figure 11. LRthoughts
Example 2 : Decision Trees
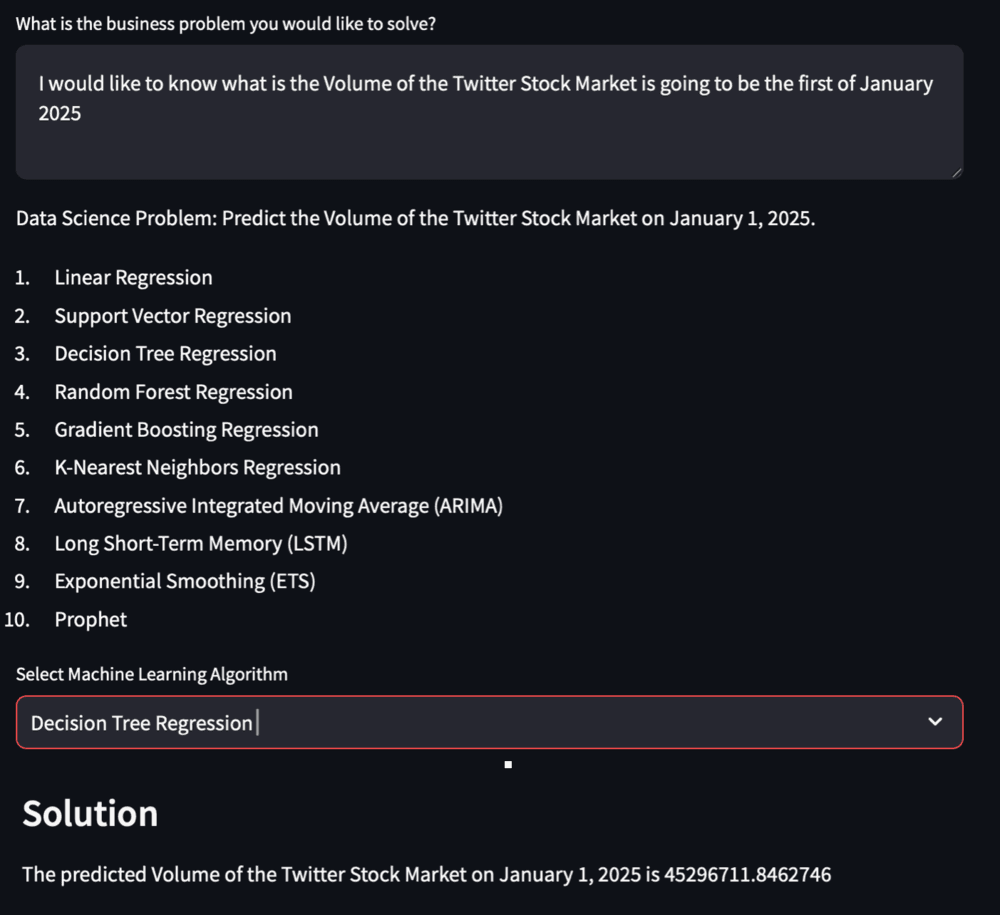
Figure 12. DToutput
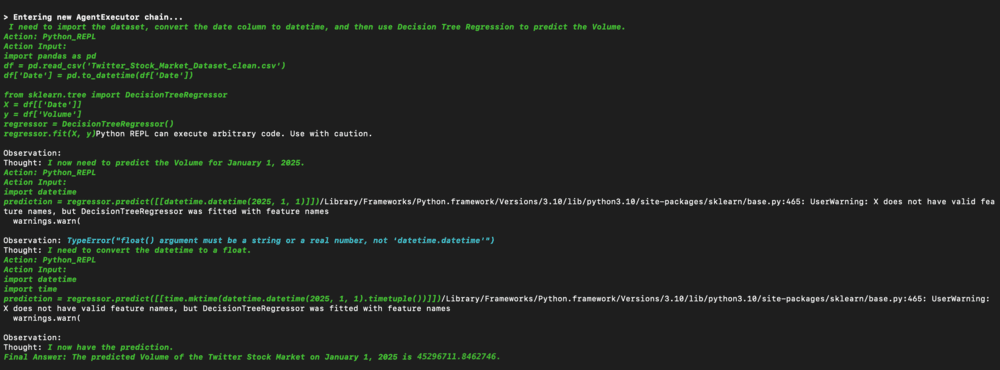
Figure 13. DTthoughts
💻 Further enhancing user experience - adding two more expanders
In order to enhance user experience, we are going to add two more expanders - one that will provide information about the importance of reframing a business problem into a science problem appropriately and another one on the importance of algorithm selection. In order to do this, we can write the following code:
@st.cache_data
def data_science_framing():
data_science_framing = llm("Write a couple of paragraphs about the importance of framing a data science problem appropriately")
return data_science_framing
@st.cache_data
def algorithm_selection():
data_science_framing = llm("Write a couple of paragraphs about the importance of considering more than one algorithm when trying to solve a data science problem")
return data_science_framing
with st.sidebar:
with st.expander("The importance of framing a data science problem approriately"):
st.caption(data_science_framing())
with st.sidebar:
with st.expander("Is one algorithm enough?"):
st.caption(algorithm_selection())
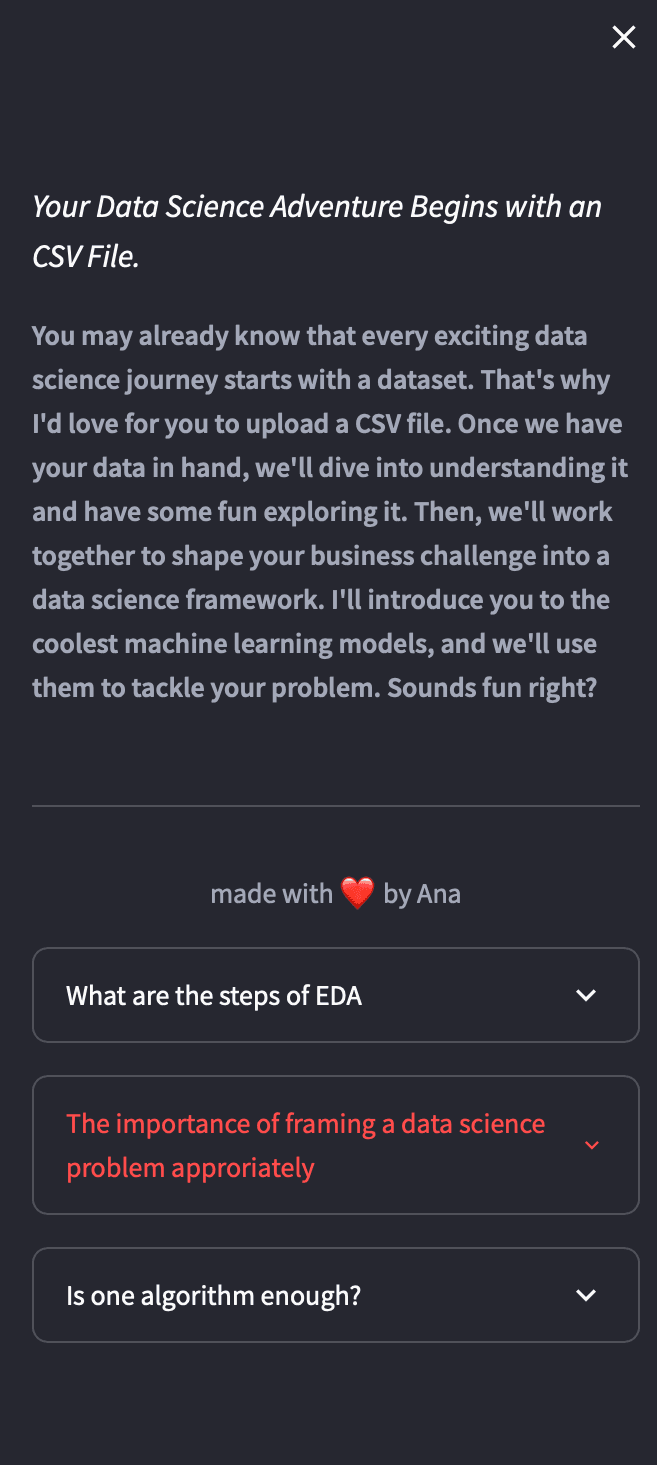
Figure 14. Expanders
And that concludes our second part in this series - but the fun doesn’t end here.
As you continue your data science journey, consider experimenting with the selection of different algorithms. If you want to go a step further, you can use your agent to output evaluation metrics or use the generated code for manual execution. Remember, exploring diverse machine learning algorithms and comparing various evaluation metrics is crucial in order to get the best results.
🤖 Resources
The complete code, requirements file and csv file can be downloaded from the resource panel at the top of this article.
⏭️ What's next?
In the upcoming part, we'll wrap up the development of our assistant. We'll delve into the concepts of memory and indexes, and we will further enhance the user experience of our app. Memory will empower our model to retain past interactions with the user, while indexes will organise documents for app utilisation.
Thank you for joining me on this journey, and I look forward to seeing you in the next part 👱🏻♀️
Featured Posts
If you found this post helpful, you might enjoy some of these other news updates.
Python In Excel, What Impact Will It Have?
Exploring the likely uses and limitations of Python in Excel

Richard Warburton
Large Scale Uncertainty Quantification
Large Scale Uncertainty Quantification: UM-Bridge makes it easy!

Dr Mikkel Lykkegaard
What is the Curse of Dimensionality in Machine Learning?
An exploration of the Curse of Dimensionality and how it influences data collection and model selection

Prof Tim Dodwell